
ALGORITMO YOLOV3 APRIMORADO para detecção de estado de segurança do pantógrafo
2022-08-02 09:13Abstrato: O pantógrafo é um componente crítico que conecta o material circulante à rede de fornecimento de energia, portanto, o status de segurança do pantógrafo é vital para a operação suave e estável do material circulante.
Neste artigo, analisando quadro a quadro as imagens de vídeo do pantógrafo monitoradas pelo sistema de monitoramento de vídeo a bordo, o status de segurança do pantógrafo é monitorado em tempo real, modificando o algoritmo de reconhecimento de alvo YOLOV3 amplamente utilizado na indústria para identificar estruturas estruturais anormalidades, faíscas e entrada de objetos estranhos no pantógrafo ao mesmo tempo. Experimentos provaram que um único canal pode atingir 40fps em um servidor de análise inteligente integrado Tienuo. A precisão de detecção abrangente mAP@0,5 pode chegar a 98%, alcançando resultados de detecção em tempo real e relativamente precisos.
1. Vigilância inteligente de pantógrafos
Os algoritmos de reconhecimento de alvo típicos de hoje baseados em aprendizado profundo são algoritmos de dois estágios, como o algoritmo Faster R-CNN e algoritmos de estágio único, como o algoritmo YOLOV3. O algoritmo YOLO não precisa calcular o quadro candidato com antecedência em comparação com o R- Rede CNN, que reduz o esforço computacional e pode atingir uma velocidade computacional mais rápida. E o algoritmo YOLOV3 melhora a deficiência de detecção multiescala da geração anterior do algoritmo YOLO por ter três ramificações na parte da rede de reconhecimento, que pode lidar com o problema de reconhecimento de alvo em três escalas: pequena, média e grande. Além disso, o algoritmo YOLOV3 tem melhor suporte de engenharia e é usado industrialmente em um grande número de aplicações. Portanto, neste trabalho,
2. Construção do algoritmo de detecção do estado de segurança do pantógrafo
2.1 Abstração de destino
A detecção do status de segurança do pantógrafo pode ser dividida em detecção de anormalidade da estrutura do pantógrafo, detecção de incêndio do pantógrafo, detecção de intrusão de objetos estranhos, etc. ângulo de proa direito ausente, etc. Os estados anormais padrão são mostrados na Figura 1B-F.

Figura 1 Estado de segurança do pantógrafo e padrões de rotulagem do algoritmo
Para usar o algoritmo de identificação de alvo, primeiro é necessário abstrair o alvo de identificação para detectar o estado de segurança do pantógrafo, e o alvo de identificação abstraído é mostrado na Figura 1. Os pantógrafos em condição normal e estado anormal são rotulados uniformemente. Os alvos como disco de proa e ângulo de proa em estado normal e disco de proa e ângulo de proa em estado anormal e faíscas e objetos estranhos são marcados. Em seguida, os dados rotulados são colocados em um modelo unificado para treinamento para identificar todos os estados de segurança dos pantógrafos de uma só vez.
2.2 Aprimoramento de dados do conjunto de dados baseado em rede neural GAN
Depois de definir o alvo de detecção, precisamos construir nosso próprio conjunto de dados de estado de segurança do pantógrafo para aprender os recursos necessários do conjunto de dados para os diferentes estados do pantógrafo usando métodos de aprendizado profundo. O conjunto de dados necessário para a construção do algoritmo neste artigo é interceptado a partir de vários modelos de vigilância em vídeo pantográfico para qualquer clima. Para reduzir a influência do ambiente nas características dos dados, as condições de trabalho como iluminação, oclusão, dias nublados, chuva e neve, entrada e saída, etc., são totalmente consideradas no processo de preparação do material de dados. Os estados de falha do pantógrafo nos dados também definidos vêm das imagens de vigilância por vídeo quando a falha do pantógrafo ocorre na forma de operação primária do trem a motor.
Considerando que alguns tipos de falhas ocorrem com menos frequência em condições reais de operação, o que pode resultar em preparação de dados inadequada. O desequilíbrio entre os dados da categoria afetará significativamente o efeito do reconhecimento do alvo, portanto, este artigo adota um método de aprimoramento de dados baseado em rede neural GAN para diferentes categorias de dados.
Generative Adversarial Network GAN contém dois modelos, um modelo generativo e um modelo discriminativo. A tarefa do modelo generativo é gerar instâncias que pareçam naturalmente realistas e semelhantes aos dados originais. A tarefa do modelo discriminante é determinar se um dado exemplo parece ser inerentemente real ou artificialmente falsificado.
Pode ser visto como um jogo de soma zero. O gerador tenta enganar o discriminador e o discriminador tenta não ser enganado pelo gerador. Os modelos são treinados por otimização alternativa e ambos os modelos podem ser aprimorados. Com base nessas duas redes, a rede Geradora é utilizada para gerar a imagem, que recebe um ruído aleatório z e origina a imagem por meio desse ruído, notado como G(z). O discriminador é uma rede discriminativa que determina se uma imagem é"real"ou não. Sua entrada é x, x representa uma imagem e a saída D(x) representa a probabilidade de x ser uma imagem real. Se for 1, significa uma imagem 100% precisa e, se a saída for 0, é impossível ser uma imagem precisa. Em seguida, a rede GAN é mostrada esquematicamente na Figura 2. x são os dados reais e os dados precisos estão de acordo com a distribuição Pdata(x). Z são os dados ruidosos e os dados ruidosos estão de acordo com a distribuição Pz(z), como uma Gaussiana ou uma distribuição uniforme. Em seguida, a amostragem é feita a partir do z ruidoso e os dados x=G(z) são gerados após a passagem de G. Em seguida, os dados reais são alimentados no classificador D e uma função sigmoide segue as informações geradas e a saída determina a categoria.

Figura 2 Diagrama esquemático do princípio da rede GAN
A transformação de imagem para imagem é uma classe de problemas gráficos e de visão cujo objetivo é aprender mapeamentos entre imagens de entrada e saída usando um conjunto de treinamento de pares de imagens alinhadas. Nosso objetivo é conhecer o mapeamento G:X → de modo que a distribuição das fotografias de G(X) seja indistinguível da distribuição Y usando a perda adversária. Como esse mapeamento é altamente restrito, nós o associamos a um mapeamento inverso F: Y → e introduzimos uma perda de consistência cíclica para empurrar F(G(X)) ≈ X (e vice-versa). Os resultados qualitativos são fornecidos em várias tarefas em que não existem dados de treinamento emparelhados, incluindo transformação do método de coleta, transformação de objetos, transformação sazonal e aprimoramento de fotos. Tanto quanto possível, são selecionadas cenas semelhantes ou semelhantes, embora contenham diferentes imagens de recursos. Por exemplo, na mesma cena, a câmera está suja e não suja; a câmera tem fotos de chuva e sem chuva. A partir dos resultados do treinamento, podemos ver que se as duas imagens selecionadas forem muito diferentes no local, os outros recursos incluídos afetarão muito o efeito do treinamento e a qualidade da geração da imagem. E se as imagens geradas a partir das cenas semelhantes selecionadas forem de qualidade aceitável, o impacto do aprimoramento dos dados é mostrado na Figura 3.

Figura 3 Efeito de aprimoramento do conjunto de dados
Além disso, este artigo também adota um método de superamostragem para expandir o conjunto de dados, combinado com a rede YOLOV3, vem com meios de aprimoramento de dados, corte aleatório de pacotes, inversão aleatória, transformação de croma e outras operações;
Os dados são efetivamente expandidos para aumentar a adaptabilidade do algoritmo e fornecer maior robustez para detectar objetos na fase de implantação de uso prático. No entanto, para distinguir entre os ângulos de proa esquerdo e direito, os interruptores aleatórios de giro e rotação são desligados no algoritmo deste artigo.
2.3 Otimização do algoritmo de reconhecimento baseado na rede YOLOV3
A parte de backbone do YOLOV3 usa a estrutura Darknet53 do autor, que pode resolver os problemas de desaparecimento e explosão de gradiente combinando rede neural convolucional (CNN) e rede de estrutura residual (ResNet), tornando possível o treinamento de redes profundas. Além disso, o algoritmo não precisa calcular antecipadamente as caixas candidatas. Ainda assim, obtém o BondingBox a priori agrupando, selecionando 9 clusters e três escalas e distribuindo esses 9 clusters uniformemente nessas três escalas. No entanto, devido ao problema de escala, a precisão do algoritmo YOLO não é a melhor entre os algoritmos de reconhecimento de alvos, principalmente na detecção de alvos pequenos. Para melhorar a precisão da detecção do algoritmo YOLOV3 enquanto mantém uma alta velocidade, o backbone do YOLOV3 é modificado. O método específico é adicionar o módulo SE de atenção do canal à unidade residual de darknet53. A estrutura da unidade de rede residual antes e depois da transformação é mostrada na Figura 4.

Figura 4 Estrutura residual do módulo SE antes e depois da modificação
O módulo SE vem do SENet, que significa Squeeze-and-Excitation Networks, obteve o campeonato de competição de classificação ImageNet 2017, é reconhecido por sua eficácia e facilidade de implementação e pode ser facilmente carregado em estruturas de modelo de rede existentes. O SENet aprende principalmente o correlação entre canais e filtra a atenção para os canais, o que aumenta um pouco a computação, mas o efeito é melhor. A parte de backbone da Darknet tem um total de 23 unidades de módulos residuais. Neste artigo, as unidades Res originais são transformadas em unidades SE-Res para algumas unidades residuais. Para melhorar a capacidade de detecção da rede YOLOV3 para alvos pequenos e médios, as unidades residuais que alteramos também estão localizadas nessas duas ramificações. A arquitetura de rede geral do YOLOV3 transformada pelo módulo SE é mostrada na Figura 5.

Figura 5 Diagrama de estrutura de rede YOLOV3
Na parte da rede de reconhecimento, o YOLOV3 é tornado mais potente por upsampling e cascata de camadas cruzadas para produzir três escalas diferentes de resultados de detecção. Na parte do projeto da função de perda, a confiança, a categoria e a posição do alvo são aprendidas de uma só vez por uma função de perda de entropia cruzada, e a função de perda é mostrada na Equação 1.

3. Análise de resultados experimentais
3.1 Introdução do servidor de análise inteligente da Tienuo
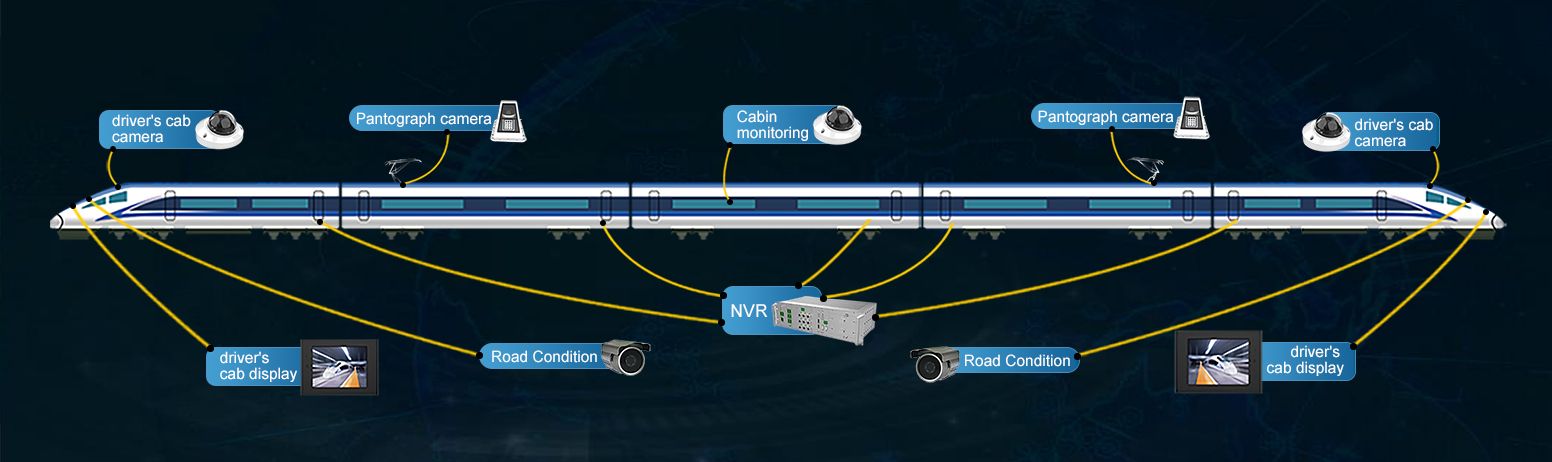
A maioria dos sistemas existentes de vigilância por vídeo em veículos possui apenas funções de monitoramento e armazenamento de vídeo, mas não possui a capacidade de análise on-line inteligente. O hardware deste artigo é implementado com a ajuda do servidor de análise inteligente integrado desenvolvido pela Shandong Tienuo Intelligent Co., conforme mostrado na Figura 6. O host é equipado com o chip inteligente AI ATLAS 3000 de arquitetura Da Vinci autodesenvolvido da Huawei, que pode lidar com aplicativos de análise inovadores na maioria dos cenários e realizar as tarefas de decodificação e análise inteligente de até 16 canais de vídeo 720p. E os resultados do teste podem ser transmitidos para a cabine do motorista ou para o mecânico em tempo real para que os resultados do teste possam ser revisados manualmente e as medidas de segurança correspondentes possam ser tomadas. Este artigo usa esse hardware para atingir uma velocidade computacional de 60 fps ao executar um único canal de vídeo da câmera. A análise simultânea de 4 canais de vários vídeos também pode garantir a velocidade de cálculo de 25 fps, o que pode atender à demanda de análise inteligente em tempo real de vídeo multicanal.

Figura 6 Servidor de análise inteligente e diagrama de interface
3.2 Resultados da identificação do estado do pantógrafo
Para detectar o estado de segurança dos pantógrafos, este artigo constrói seu próprio conjunto de dados de estado de segurança do pantógrafo, contendo 2388 imagens de várias formas de pantógrafos, incluindo pantógrafos em estado normal e imagens de monitoramento de pantógrafos em estado anormal sob diferentes condições de trabalho. O conjunto de dados rotulado é treinado usando a estrutura darknet e o processo de treinamento é mostrado na Figura 7. Pode ser visto na figura que a perda de treinamento permanece estável após 12.000 iterações e o modelo pode cair em um ótimo local. A taxa de aprendizado é ajustada uma vez em 20.000 iterações e a perda cai para menos de 0,1. A melhoria na precisão computacional de 20.000 iterações em diante não é significativa, e o gráfico mAP correspondente mostra uma pequena perda na capacidade de generalização do modelo. Para considerar a perda de treinamento e mAP,

Figura 4 Processo de treinamento de identificação do estado de segurança do pantógrafo
Para implantar o modelo treinado no host de análise inteligente, o modelo treinado precisa ser convertido para o formato om suportado pela arquitetura Huawei da Vinci, com uma pequena perda de precisão no processo de conversão, mas tudo dentro de um intervalo aceitável.

4. Resumo e prospecto
Este artigo usa o algoritmo YOLOV3 para detectar o status de segurança de pantógrafos, incluindo anormalidades estruturais, faíscas e intrusão de objetos estranhos, por meio de monitoramento de vídeo em tempo real, levando em consideração a velocidade de detecção e garantindo que a precisão da detecção atenda aos requisitos de real- análise de tempo. Ele fornece novas ideias para usar um sistema de análise inteligente a bordo em uma inspeção de segurança de pantógrafo.